

In the world of video, timecode is everywhere.
It’s the universal language we can use to describe a single frame of video. It’s easy to understand, simple to implement, and readable.
Every video workflow either relies on timecode, or at least need to be compatible with it. And yet timecode is, in its current state, insufficient for the future of video workflows.
But before we look ahead, let’s take a look back.
What is timecode and why do we use it?
Timecode is so prevalent that we tend to take it for granted. But what is it, actually? If you think it’s a synchronization tool, you’re not wrong. But that’s not why it was developed.
Before video tape, all media was shot and edited on film. Reels of film used a system developed by Kodak called KeyKode, also described as Edge Codes. Edge Codes labeled each frame of film so that editors knew exactly what they were looking at and could communicate that to other people.

By the 1950s, however, video tape was becoming more widely used in television. At the time, there was no Edge Code equivalent to label frames on tape, so editors couldn’t tell what frame they were cutting on. A few interesting solutions were explored—like using pulses on the audio track—but it wasn’t until much later that a standard was implemented: ST-12.
ST-12 was proposed by SMPTE in 1970 as a universal labeling system for frames on video tape. In this standard, each frame would be counted at a specific rate: frames would make up seconds, seconds would make up minutes, and minutes would make up hours. This, of course, would then be displayed to look like a clock: HH:MM:SS:FF.
And in 1975, SMPTE approved the standard and timecode was born.
Timecode is not time
But there’s a very important takeaway from timecode’s history: its original purpose was to identify a certain frame within a piece of time-based video media. It’s a way to pick out a specific frame in context. An address. A label. Not actual time.
It’s represented as time, but timecode is not time. Because it resembles a clock, it can be used to synchronize discrete pieces of media. If each capture device sets its timecode “clock” to the same value, then the frames or audio samples they record will have the same label.
We think about timecode as time because it looks like a clock, but two cameras with the same timecodes don’t sync because their frames were captured at the same time—they sync because they have the same label.
The crucial nuance here is that the label is arbitrary. If we set it to be the same, then devices can sync; but they don’t have to be the same. Again, timecode is not time.
Two cameras with the same timecodes don’t sync because their frames were captured at the same time—they sync because they have the same label.
Going back to ST-12, the problem it was solving was for video tape workflows. This meant the solution needed to be consistent and lightweight, which led to the limitation of hours, minutes, seconds, and frames. Restart the timecode on different media, or roll past the 24-hour mark—which flips back to 00:00:00:00—and you end up with different frames with identical timecodes. And that’s a problem.
To counter this, we use “reel” or “tape” IDs in our post-production tools. This secondary identifier is necessary to separate frames with potentially matching timecode values. But reels and tapes are single pieces of continuous media. In the file-based digital world, this concept is no longer relevant. Each clip is its own whole asset.
Suddenly, we’ve gone from a few assets containing many frames to many assets containing a few frames. So finding assets with overlapping timecodes—i.e., unrelated frames with identical labels—is now a much more common problem.
Not worth the time
Looking at the origin and initial purpose of timecode, we start to see how it can quickly become limiting. On the one hand, it’s arbitrary: there’s no way to enforce a universal sync of timecode values across all devices, everywhere, at the same time. Sure, an entire production set can be jam-synced, but there’s no actual automatic enforcement of that process. It’s not a guarantee.
Similarly, there’s no way to enforce the value of that timecode. While it’s common to use “time of day” (or “TOD”) timecode—i.e., values that match the clock of the current time zone—it’s also common to use an explicitly arbitrary value.
This is often necessary when productions are shooting at night. In these cases, setting the timecode to 01:00:00:00 at the start of the production day eliminates another major problem with today’s timecode format: midnight rollover.
Since timecode uses time units to represent its values, it’s limited by a 24-hour clock. If you shoot using TOD timecode and then shoot across midnight, your timecode clock resets back to 00:00:00:00 in the middle of your shoot, causing labeling and sync issues.
Time and space
These constraints disappear in the digital domain. Files can carry large amounts of additional data alongside their media elements. In the sense of acquisition (ie, takes), files are discrete moments. They have defined beginnings and endings and, typically, unique identifiers.
Since they’re created by computer systems, they can also record when and, more and more frequently, where in real time and real space they were created.
Not only is digital media creation file-based, it’s also increasingly distributed and cloud-first, which widens the context that media is created within.
Moreover, as high-speed mobile networking continues to improve, traditional means of transmitting a video signal will be replaced by file-based and IP solutions. Both of these make identifying unique pieces of media and their component units much more complex than it was in the days of videotape.
It’s clear that timecode as a label is insufficient. As a means of locating a specific unit of an asset (ie, a frame) and identifying it in time, timecode is both arbitrary as well as imprecise. So now is the time for an updated standard—one that takes advantage of the benefits of a fully digital, file-based, cloud-first production world.
If we can rethink the way we record and describe a moment of time—just as we’ve revolutionized the way an image or sound is recorded—we’ll start to see how this doesn’t just give us more information to work with. It becomes an entire pipeline in and of itself.
For example, streaming video could be traced back to its source—a specific moment of time recorded in a specific point in space. With the rapid adoption and advancement of AI-driven video like Deep Fakes, being able to maintain and establish the veracity of any given piece of media is paramount. It may even become a matter of national security, which raises the topic of encryption.
So let’s take a look at the places where a new solution can solve the modern issues of ST-12.
The problem of size
At the core, all time-based media creation—film, video, audio, etc—is the process of freezing multiple moments of time at a certain rate within certain boundaries.
It’s easy to look at a specific timecode value and assume it refers to a discrete moment. A single point of time. In reality, a single timecode value (ie, a frame), is actually a range of time. It’s a sample of continuously running time.
For example, take the timecode label 03:54:18:22. At 24 frames per second, instead of representing a precise moment, that single frame label actually represents almost 42 milliseconds of time. 42 milliseconds pass from the moment that frame was captured or is played back to the moment the next frame starts.

42 milliseconds might not sound like much, but it’s a large sample of time that makes labeling imprecise. Which becomes evident when you mix media with sample sizes that are very different—like video and audio.
The time range of a video sample is much longer than the time range of an audio sample. At 48KHz, there are 2000 audio samples to every video sample. This means that there are also 2000 audio samples for each timecode label.
Even though the sound department is typically responsible…timecode itself is wholly inadequate to label audio samples.
Even though the sound department is typically responsible for the timecode on a production set, timecode itself is wholly inadequate to label audio samples. (In fact, this is why many sound recorders start their files at a whole second—it makes synchronizing to video in post much easier.)
In order to reconcile this difference in sample resolution during post production, audio usually needs to be adjusted at a sub-frame level to line up with the video. This is often called “slipping”. Another term you may see is “perf-slipping”, which refers to the process of slipping audio (in this case, audio tape specifically) by increments of perforations on a filmstrip—usually 1/3 or 1/4 of a frame, depending on the format.
Too broad and too narrow
In this sense, timecode is too broad or coarse to accurately and precisely label time. On the other end of the spectrum, we also have the format’s 24-hour time limit before rolling over to 00:00:00:00.
What this means is that there is a fixed and limited amount of unique timecode values. When using TOD timecode, these values are repeated every 24 hours. When running at 24fps, there are only about two million unique labels in a 24-hour period.
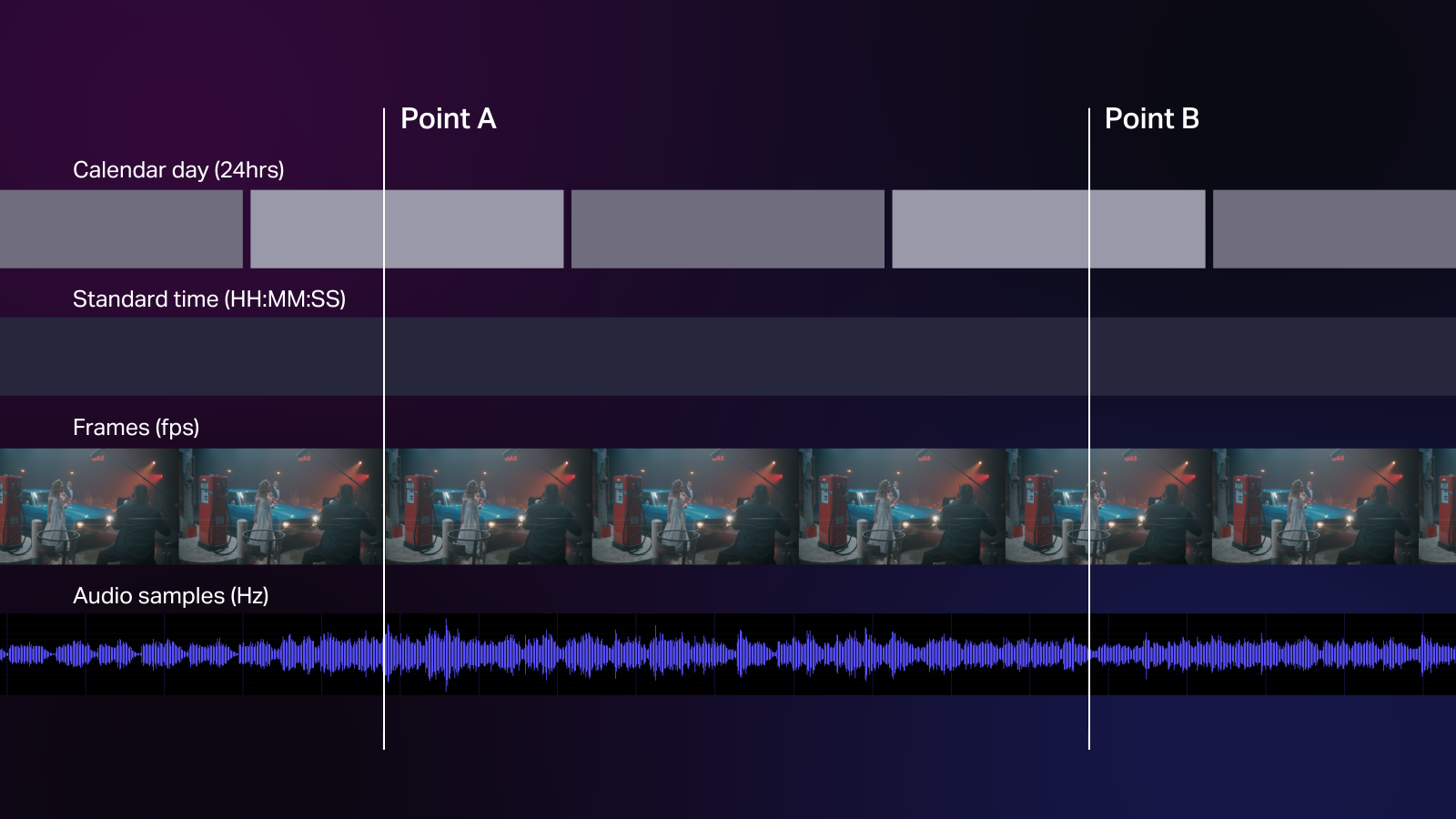
For example, if a production is using TOD timecode for both video and audio, takes recorded on Day 1 will have the same timecode values as takes recorded on Day 2—even though they describe different points in time and space.
The problem we see here is that timecode is simultaneously too broad on the one end and too narrow on the other end. But the other problem of size is that the actual base unit of timecode—the frame—is not itself a fixed size. A frame can be 1/24 of a second, 1/25 of a second, 1/30 of a second, 1/60 of a second, and so on. While frames are a fixed size when they are recorded, timecode has no way to indicate what the size of the frame is.
Separately, timecode also doesn’t allow for the frame rate itself to be variable. A variable frame rate would allow for the duration of each frame to change for encoding reasons or even creative effect. Using frame rate as a creative tool is a fascinating concept that’s currently blocked by the limitations of ST-12.
The difference between 60fps and 24fps is dramatic for viewers, and can be used effectively, but what about 33fps? What effect might you get from subtly shifting from 21fps to 29fps? Or simulating 2- or 3-blade film projector judder? The video game industry has set a precedent for using frame rates creatively and this is a technique absolutely worth exploring in video production. Assuming we can find a standard that can support it.
Timecode also blocks workflows that might want to super-sample time resolution the same way we super-sample video and audio resolution. Imagine workflows where acquisition could happen at one frame rate (say 120fps), while proxies could be created at a lesser frame rate (say 60fps) to ultimately finish in another (say 24fps).
Workflows like these would eliminate the need for optical flow frame interpolation and over-cranking (except at extremely high rates). Footage could effortlessly switch between different rates and creators could choose in post the timing of a moment. Motion blur and shutter effects would be post-production effects. The photography would create not only more frames, but also sharper frames, giving VFX much cleaner tracking and masking.
The problem of location
We’ve already mentioned labeling moments in both time and space. At present, timecode gives us a label we can work with for time (albeit with limitations), but not for space—specifically location. And time and location have an interesting relationship that further complicates things.
Most of this complexity comes in the form of time zones. As workflows move toward cloud-first and become more and more distributed, it’s more important than ever to be able to localize timestamps so that time references make sense relative to location.
Workflows that employ instant dailies—like Frame.io C2C—illustrate this very well. A media file that’s uploaded was recorded at a specific time in a specific location, but can be accessed and interacted with instantly from any other time-location on the globe. It therefore doesn’t exist in a specific time-location in any practical way, except as a means of identification.
When a reviewer leaves a comment on a piece of media with TOD timecode from a different time zone, which time is correct?
This gets further complicated with interaction. It’s possible (and, in fact, quite common) for a comment or note to be applied to an asset from a different time zone than from where the asset originated—or even where it physically “lives” currently. When a reviewer leaves a comment on a piece of media with TOD timecode from a different time zone, which time is correct?
Alternatively, productions can use this time+location fluidity to their advantage to overcome a different timecode limitation. As we’ve already discussed, overnight productions may set their timecode “clock” to start at 00:00:00:00 or 01:00:00:00 to avoid the “midnight rollover” problem.
If you don’t want your timecode to cross midnight, just move midnight to a different time zone. This is a clever solution to a tricky limitation, but it also highlights how fragile and arbitrary timecode is—timecode is not time.
The problem of perspective
Everything we’ve gone over so far is a problem, sure, but certainly manageable when you’re working with one video source and one audio source.
But everything gets exacerbated when you add more perspectives. The same moment in time can be interpreted very differently by different points of view. But capture technologies have a very limited point of view—video, audio, or data—which is why there are often multiple devices used simultaneously to capture as much information and perspectives on a single moment of time.
In a typical acquisition setup, we have video and we have audio. These are two perspectives on a moment that are unique to each other. They both describe the same moment, but with wholly different resulting media. In this example, timecode works pretty well to bring them together. If they share timecode values and are “synced”, then the overlapping timecode tells us they describe the same moment. And, in this case, one is video and one is audio.
However, this gets predictably more complex as we add more perspectives—say an additional camera or two. We can synchronize all of these perspectives’ timecodes together, but now we face the problem of several sets of media that not only share overlapping timecode labels, but also data types. It’s now much more difficult to identify one frame from another one.

During post-production, we now have several sets of duplicate frame labels. There’s nothing in the label itself to tell us if a given frame is from camera A or camera B.
There is no inherent connection here; instead, we end up using an additional layer of technology to identify a frame in a unique way. For video, this is usually done with Roll, Tape, or ClipID embedded in the metadata, but there is no guarantee a given camera will embed or support that metadata—in fact, there’s no guarantee a camera will even name its files uniquely. Many professional-grade cinema cameras do, but it’s not a guarantee.
Finally, as media is moved from generation to generation during post-production, that metadata may be lost and will instead have to be transported in a separate file—often an ALE or EDL.
While the most obvious examples of different perspectives in production are video and audio, it’s fair to say that motion, telemetry, lighting, script notes, and more all constitute other points of view on these moments of time. They all describe the same thing through their specific and distinct perspective, each adding to the complete picture.
Every year, the number of data types being recorded in production continues to grow. And because each of these is describing a moment in time, they too need viable time labels. This is not what ST-12 was designed for.
Today, a given moment of recorded time has an incredible amount of data associated with it. The intersection of creation and time labeling needs a time label that’s also aware of its point of view. A time label that is also media identity. Knowing when something was created is not enough to know what it is.
Yes, we can currently use timecode for synchronization. We can use it to reassemble our disparate perspectives together in time. But the problem is timecode only really supports frames of video.
In contrast, audio timing is derived from the sample rate and a capture of the timecode value at the start of recording. It doesn’t inherently have a timecode standard. And the same is true of other data-centric types like motion capture, performance capture, telemetry, etc., which are all essential for virtual production. These types may be sampled per frame, but they may also be sampled at much higher resolutions. Additionally, this data is file-first. They receive a timestamp from the computer system that creates them at the moment of creation—which is relative to the time of day of the computer.
Since timecode is arbitrary and may not use time of day as a reference, there’s no way to effectively bring these into synchronization.
The problem of generation
Naturally, the lifespan of a piece of acquired media extends beyond the capture phase.
The whole reason we want to identify media in time is so that we can assemble it with media from other perspectives to create our program. The timelines and sequences we place our timecoded media into have their own timecode, since each frame in the edit should have a time label that’s relative to the edit.
This means that as soon as timecoded media is placed into a timeline, frames now have two distinct timecode values associated with them: Source timecode (the time labels embedded in the source media) and Record timecode (the time label assigned by the timeline). These terms both come from linear tape editing—Source timecode was the timecode of the “source” tape and Record timecode was the timecode of the destination (or “recorded”) tape.
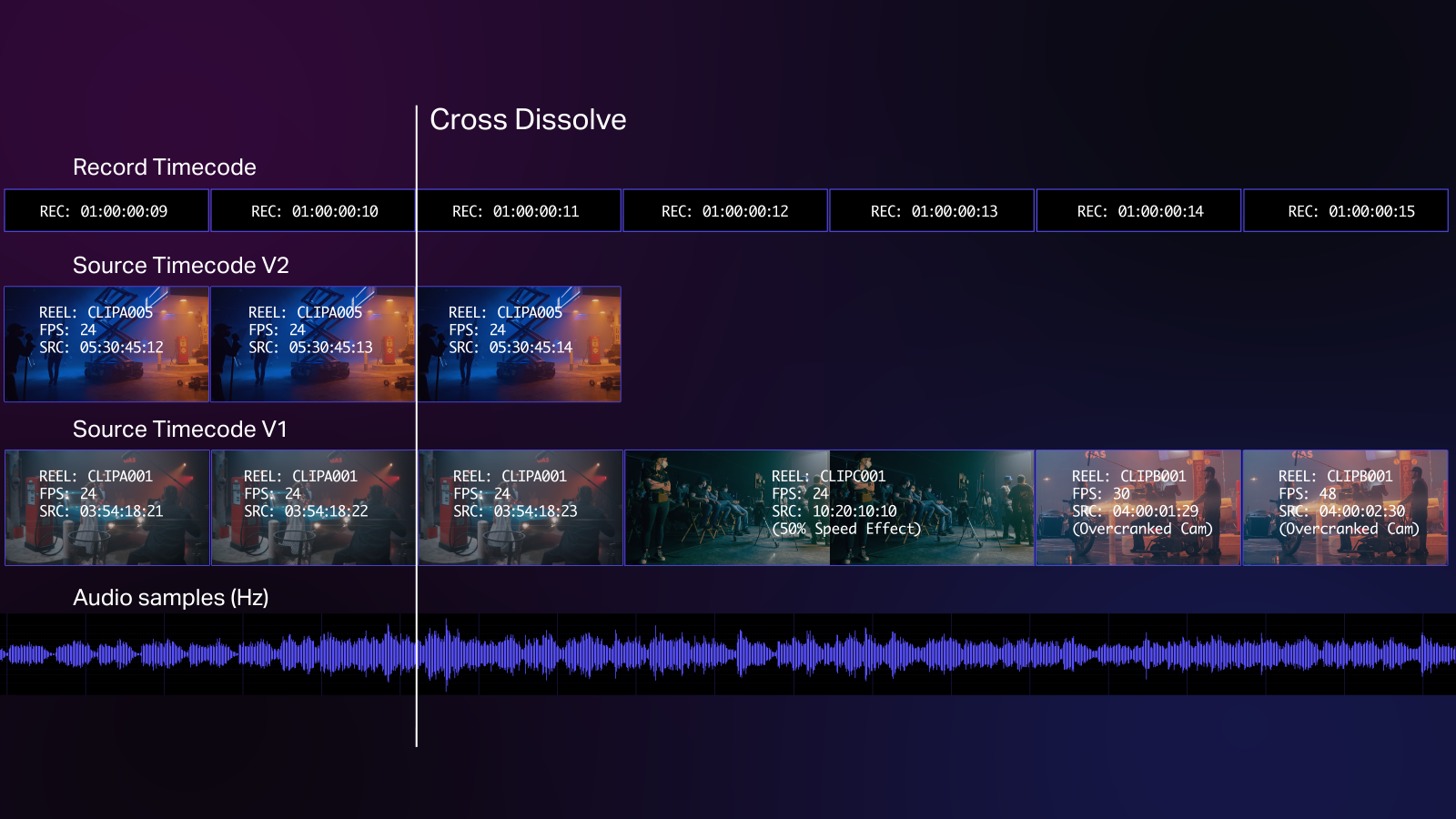
This of course compounds as more layers of concurrent media—like synchronous audio, camera angles, stereoscopic video, composite elements, etc—are added to a timeline. And it gets even messier when an editor manipulates time with speed effects. Once these effects are used, the source time label becomes irrelevant because the link between the content of the frame and its timecode value is broken.
Once these effects are used, the source time label becomes irrelevant.
While the timecode of a timeline can start at any value, it most often starts at whole hours—usually 00:00:00:00 or 01:00:00:00. Though long programs like feature films might be broken into several reels.
Reels are timelines that only contain a section of a program—usually about 20-25 minutes, similar to the length of a reel of film. When a program is in reels, the starting timecode of each timeline might represent the reel number so that the first reel starts with 01:00:00:00, the second reel starts with 02:00:00:00, and so on. Again, this is a clever way to manipulate the arbitrary nature of timecode to inject more information into the label.
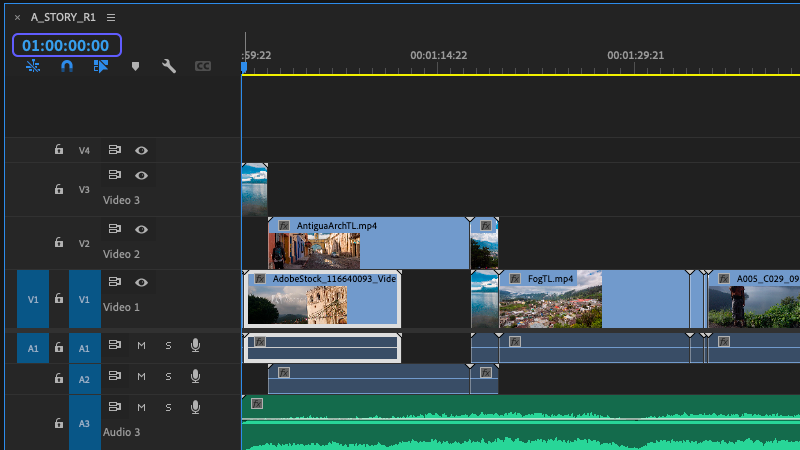
Once we start editing, we now need to track both where an asset is in a timeline (or several timelines) as well as which frames of the original asset are being used in a given timeline. And, again, lists like EDLs are designed to do just that, but edit lists exist outside of both the timeline and the asset. Source and Record timecode together can give us context about where an asset is being used and what part of it is being used. Individually, neither gives us any true identifying information.
Source timecode by itself tells us what part of the asset is being used, but not where. Record timecode by itself tells us where in a timeline an asset is being used, but not which asset or which part of it. We need more. We need to store, track, and manage timecode elsewhere with other identifying information like reel, tape, or clip name.
The problem of context
One of the issues at the core of these problems is that there’s necessary context that needs to accompany timecode in order to truly identify an individual frame.
A simple timecode value tells us very little about the frame it labels—we don’t know what created it, what it is, how long it’s supposed to be, or how it’s being used. While ST-12 does offer space for what’s called user bits—which can be used for this—there’s little standardization in the industry on how to use these bits.
This brings us back to the mantra of this piece: timecode is not time.
If we keep thinking of timecode as a clock, we’ll tend to use it not only to identify that frame in time, but also identify it as unique among other frames. This use is why we work to avoid midnight rollovers. But, as we discussed, there are only so many unique timecode values inside of a 24 hour cycle; repeating a timecode value is unavoidable.
There are only so many unique timecode values inside of a 24 hour cycle; repeating a timecode value is unavoidable.
To help provide the missing context, we usually associate additional relevant data that may not be strictly time-based to time-based media (slate, color correction, script notes, LIDAR, and so on). Today, we try to use timecode to tell us both what and when a piece of media (or a unit of media) is, but even with user bits, ST-12 does not carry enough information to do that effectively.
Even if much of the data we want to include with media is not time information, it’s still necessary when using a time-related label to uniquely identify the smallest unit of a piece of media within the context of the original media asset (i.e., identifying a frame inside a video file). Also within the context of other, external assets (i.e., identifying a frame from video file 1 as different from a frame from video file 2).
This is not a radical idea; there are a number of methods for organizing production media. For example, most professional-grade cinema cameras embed their own metadata schemas into their recorded files.
If we were to create room for contextual data in a time label specification, we’d open up many new possibilities. On a basic level, this would allow us to identify a frame or sample in both time and context across camera manufacturers, video hardware manufacturers, and software developers simply by standardizing a place to store data.
Timecode as identification
Let’s revisit the initial purpose of timecode, which is labeling. We’ve been talking a lot about the problems of timecode, but in truth it’s quite a brilliant solution for what it set out to be.
It can serve two purposes of identification simultaneously: it can create a unique media identity on a video tape (or inside of a digital file) and it can also identify a specific moment in time. Timecode creates a bridge between real time and media.
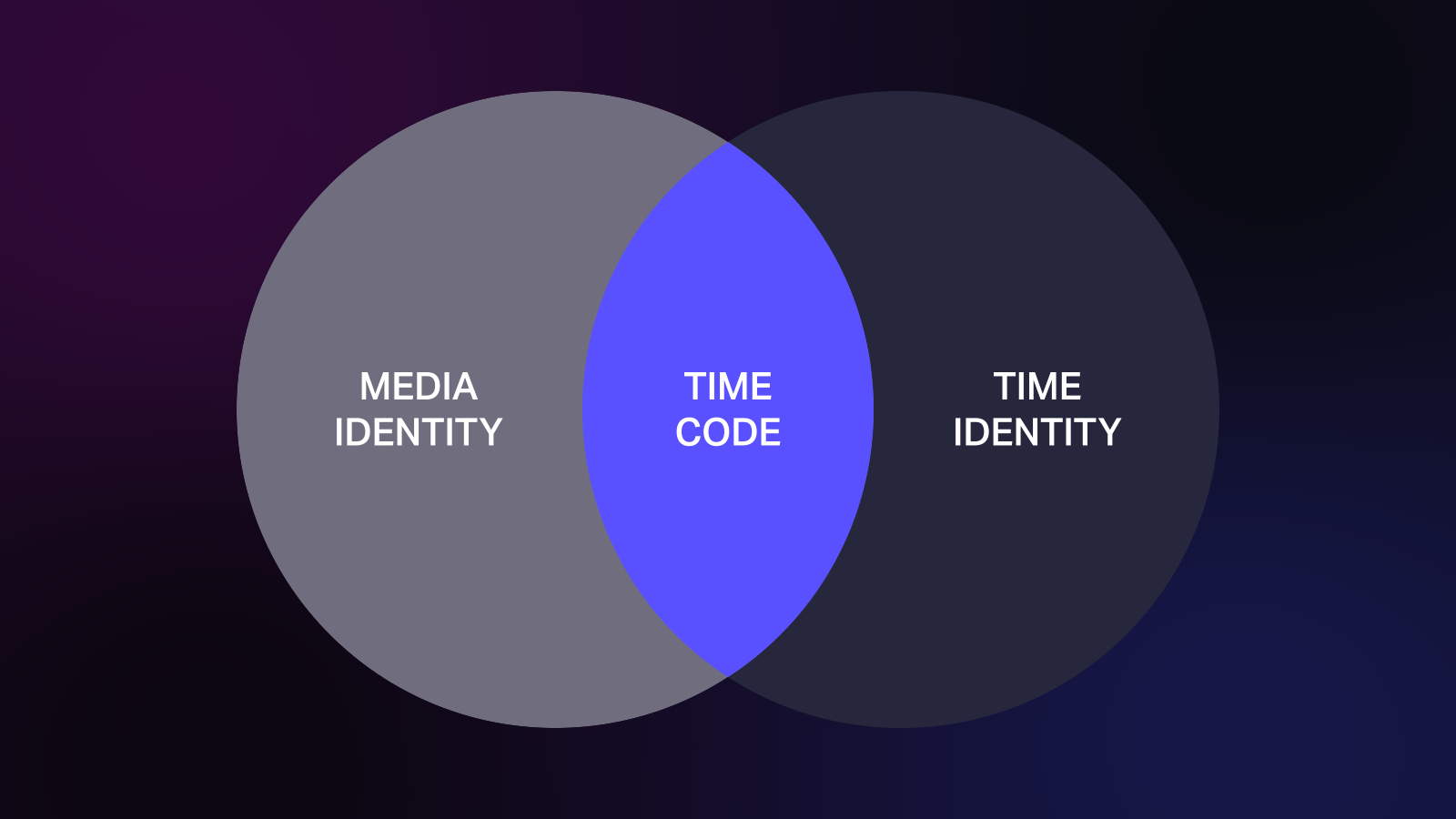
But the key here is that, while timecode can do both of these things, it can only do them within the context of a piece of media (like a video tape). Media identity is not time identity. They each have their own set of attributes and needs to enhance their use and functionality for modern workflows.
Media identity requirements
- Can be used to locate and identify a single unit of time-based media (like a frame or audio sample) within a single media asset,
- Can be used to locate and identify a piece of time-based media (or a single unit of time-based media) in the context of other media assets,
- Can be used to trace the origin of a piece of time-based media.
Time identity requirements
- Can be used to locate a single unit of time-based media in time,
- Can be used to locate a piece of time-based media’s origin in time,
- Can be used to identify sample rate of a piece of time-based media,
- Can be relatable to real time and be human-readable.
While media identity and time identity are different from each other, they are inextricable and there is a lot of value in using a single standard to store and track them together.
Finding a new standard
We’ve looked at a lot of ways ST-12 feels insufficient for modern, file-based, cloud-first workflows. So how do we replace it?
The first thing we need to do is set a framework for what a new standard would need to provide. A new labeling standard should:
- Be able to identify the smallest unit of an asset (ie, frame or sample) as unique from other units and other assets,
- Be able to identify how assets relate to each other in time,
- Be data-rich,
- Be able to be easily implemented into existing and future file containers,
- And be backwards-compatible with ST-12.
But outlining what a new standard should do isn’t quite enough. We need to also set up guardrails to ensure the new standard will be successful into the future. To do that, we need to make a few assumptions. In the future, it should be assumed that:
- Video transmission will disappear, to be replaced by file transmission,
- All hardware will be connected to the internet,
- All original assets will transmit to the cloud on creation automatically,
- And video, audio, and time resolutions will increase for the purpose of super-sampling.
Working with these assumptions and future automated workflows in mind, a new solution should be network-based, driven by metadata, and extensible.
Timecode 2.0 should be able to carry blobs of data per frame. Since everything in acquisition (with the exception of the actual photons) will both originate and be delivered on computerized systems, this data will need to be easily read by code and easily transported into software.
Additionally, while these data blobs should have a standard schema for core information, they should also be extensible by manufacturers and designers. For instance, the schema should have a standard location for a timestamp, but a camera manufacturer may want a place to put in their custom metadata.
When it comes to time, timecode 2.0 should rely on internet-provided, localized time of day with date. It should also store the sample rate and sample size.
If we know the exact moment (down to the millisecond) when a sample was captured as well as how long that sample is (or at what rate per second samples were captured), each individual sample can be identified as being truly unique in time. This solves the “too narrow and too broad” problem by providing a level of identification beyond 24 hours and the ability to track the individual samples in relation to actual time.
But ST-12 has been around for almost fifty years, and it’s not going away any time soon. But by looking at the internet-provided time of day and date, and the sample rate, we can calculate an ST-12 compatible value to add to the file. This way, the new standard can be backwards compatible with timecode enabled tools.
Here’s an example of what a time label expressed as JSON could look like:

Time pipeline
If we arrange a new labeling standard as data, we can also add other information.
And, since in the future the data will be handled exclusively by computerized systems, there’s no real limit to how much data can be stored. For example, we can begin to track manipulations to the time identity as layers.
With the concept of layers of time, a file can carry information about each generation of a frame: from origin, to edit, to effect, to delivery. Each new layer can become simply a new entry in the data blob.

As we layer this information on, we start to see the pattern of a new pipeline emerging. Over the past few decades, there have been incredible advances in camera technologies that create images that have amazingly high resolution, wide gamut color profiles, and efficient encoding profiles. Display technology has also had its own share of major advancements in things like spatial resolution, contrast ratios, screen thickness, and energy efficiency.
Post-production standards and pipelines have reacted to these advancements and evolved to handle more data. NLEs can now support multiple resolutions in a single timeline. Advanced color workflows, like ACES, create pipelines for managing the lifecycle of color manipulation. Dolby has developed pipelines for varying audio and color environments with solutions like Atmos and Dolby Vision.
But there’s been very little advancement in the way we track manipulations to time. A new data-based standard can provide that. The idea of a pipeline for time brings with it a significant opportunity—trust.
A time pipeline could provide a means to trace a frame through manipulation back to its origin. This could be used to determine the authenticity and veracity of a given frame. With the rise of AI manipulation like Deep Fakes, the ability to go back to a frame’s origin could become a fingerprint for that sample.
But this raises a serious question: if we can use this to trace a sample back to its origin, how do we protect the data itself from being manipulated? Further, if we can identify exactly when and, importantly, where a frame or sample was created, how do we ensure privacy is maintained? Imagine a documentary shooting a sensitive interview. This data should not expose anyone to potential harm, so there must also be provisions for encrypting it.
Proposed solutions
Looking for a successor to ST-12 is not new. Several proposals like ST-309 or RDD 46:2019) have been put forth to expand it. Other solutions, like the TLX Project, seek to replace it.
Finding a solution is a complex problem and requires no small amount of forward thinking. A solution needs to not only work with existing workflows, but it needs to empower the cutting edge workflows of today and the workflows of tomorrow that have yet to be created.
The TLX Project being developed at SMPTE is the most comprehensive of the proposed solutions. “TLX” comes from “Extensible Time Label”. It addresses many of the limitations we discussed as well as many of the requirements outlined here.
The goal of TLX is to create a time label that has high precision (solving for the “too narrow” problem), a persistent media identifier, and can be extended with custom information. TLX has the concept of a “digital birth certificate,” which provides a media identity that is unique and transportable. Additionally, it would provide a “Precision Time Stamp” based on IEEE 1588 Precision Time Protocol. This would give the media a specific and unique time identity.
Conclusion
Despite all the advancements in capture technology for image, sound, and data, there have been few significant advancements with regard to capturing time.
There have, however, been impressive improvements in both capture and encoding technologies that operate over time. Frame rates get bigger as camera bodies get smaller. There’s also been much work with variable frame rates in encoding and asset exhibition.
But how can we connect the dots on the handling of time all the way through the process, much in the way that the Academy tackled the multi-phase journey of color through a media creation pipeline with ACES?
Time serves not only as the backbone of our workflows, but also as a core definition of what we are creating:
<b>media = (image + sound) * time</b>
And so, the way we record, transmit, translate, and interpret time data needs to catch up to our modern workflows. Moreover, it needs to evolve to ultimately allow more powerful and efficient workflows while also unlocking creative potential that was previously impossible.
It’s time to talk about time.


